Overview
Below are suggestions that can improve packager performance. Which suggestions may be most relevant can depend on which stages of packager are showing longer times spent in the packagerReport.html and/or which packaging folders and script types are showing longer times spent. The first step is to look in your packager reports to see which stage(s) of packaging are taking the most time.
Note that although turning off certain features and settings can improve performance time, it can be a trade off since you may lose functionality. Which features and settings to narrow down the scope of or disable may be different for each customer.
Please contact our Technical Support team if you would like assistance analyzing the timing shown in your packager reports and adjusting the settings that are relevant for your environment.
Timing in packagerReport.html
First run deployPackager and obtain timing data on the complete workflow in the packagerReport.html. You may want to run packager multiple times, with different types of scripts committed in different folders. The timing will likely be different for some types of scripts compared to others because packager uses different processes. Such as timing for ddl folder (when using the default ddl packageMethod=convert) versus timing for sql_direct folder (uses packageMethod=direct) versus timing for function/procedure/etc stored logic folders (uses packageMethod=storedlogic).
Each packagerReport.html has six main sections:
- Overview - Scripts Processed
- Additional Logs & Reports
- Deploy Packager Phases
- Runtime Environment Properties
- Packager Configuration Properties
- All Properties
Here is an example of the whole report (click image to enlarge):
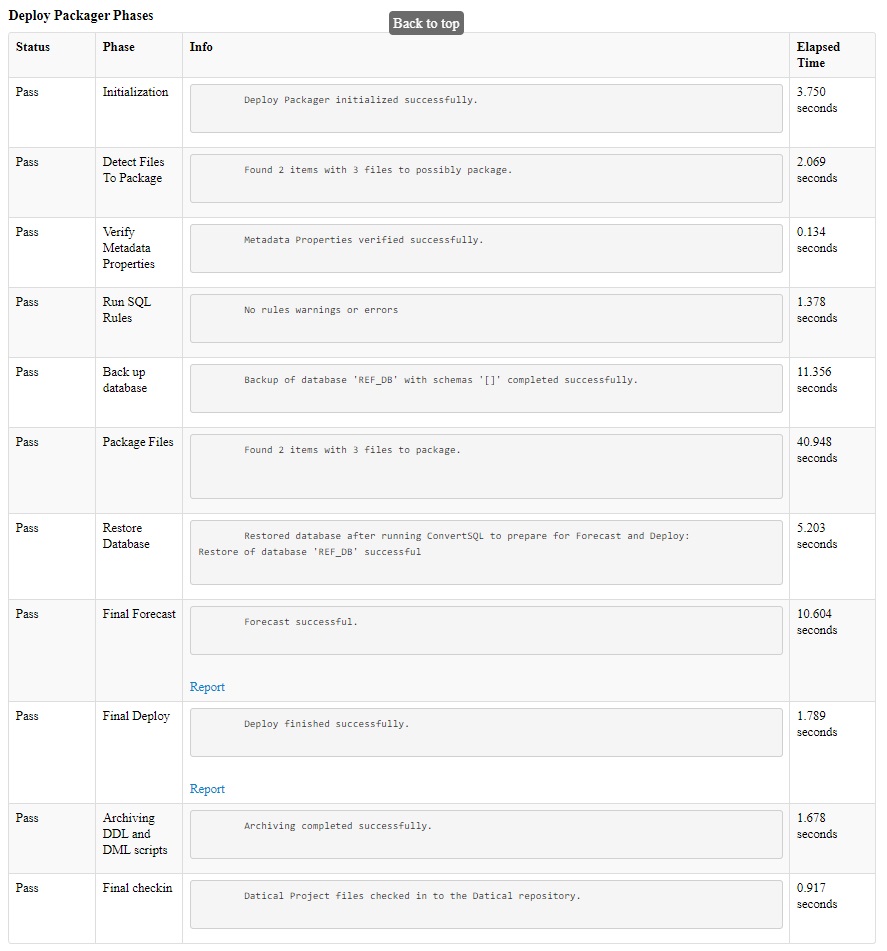
For analyzing performance timing look at the third section called Deploy Packager Phases. The Deploy Packager Phases section breaks down the timing for each stage of packager:
- Initialization
- Detect Files to Package
- Verify Metadata Properties
- Run SQL Rules
- Back up database
- Package Files
- Restore Database
- Final Forecast
- Final Deploy
- Archiving DDL and DML scripts
- Final checkin
The Deploy Packager Phases section shows the timing for each stage (click image to enlarge):
Items that can affect Packager Performance
1. When managing multiple schema in a multischema project, use the optional "schemaName" property in the metadata.properties file. Here are details about it:
- When configuring the repository for your SQL scripts, you may now specify which schema a script applies to in a multi-schema project. This will allow the Deployment Packager to limit it's change detection & recovery capabilities to only those schema that are impacted by the scripts being processed during that packager run.
- For example: If there are 30 schema in your project, but there are only scripts for 4 of the schema in this packaging run, then packager will be limited to the 4 relevant schema for that packaging run (instead of all 30 schema). This can shorten the packager run time. This only works if all of the scripts for that packaging run have the schemaName property set in the metadata.properties files in their folders.
- To configure, set the value of a 'schemaName' property in the metadata.properties file for a specific directory. The value can be one schema name or a comma separated list of schema names. Do not put quotes around the schema values with Datical versions 6.12 or lower. It is important to use casing for the value of the schemaName property that matches the casing of how your schema is listed in your datical.project file. For example: schemaName=SCHEMA1. Please see this page → Using the metadata.properties file
- Setting this property does not affect script execution in any way. It is used internally by the Deployment Packager to limit the scope of operations by schema.
- We recommend using either schemaName property OR backup on demand:
- If you are using backup mode "always", then the schemaName property will limit the schema list to the relevant schemas for three aspects of packager: backup, restore, and snapshot.
- However, if you are using backup mode "on demand" then the schemaName property will limit the schema list to the relevant schemas for only one aspect of packager: snapshot. When you set backup to "on_demand" all of the schemas in the project will be backed up and restored, the schemas for backup/restore will NOT be limited based on the schemaName property.
2. If packaging scripts in the "ddl" folder (when using Fixed Folders) or packageMethod=convert (when using Flexible Folders) is slow, consider using the optional "ddlExcludeList" property in the deployPackager.properties file to exclude certain object types from the snapshots that are used for before and after comparisons with ddl scripts. If you are packaging stored logic objects in their recommended corresponding packaging folders (such as packaging function scripts in the "function" folder, and packaging procedure scripts in the "procedure" folder) then you do NOT need to have those object types in the snapshots used by the convert method when packaging ddl scripts in the "ddl" folder. Excluding stored logic object types from the snapshots used in the "ddl" folder can improve performance, especially if you have a lot of stored logic objects in your database.
Please see "ddlExcludeList" in this document → Using the required deployPackager.properties file
3. Use backup "on_demand" to create static backups, such as a nightly backup that can be used by packaging jobs as needed. You would have two different automation jobs. One job is your existing packager job that processes your new sql scripts. The other job will be a job that runs packager in preview mode each night to only create the backup file. Please see this document for the appropriate settings for each job → Managing Database Backup and Restore
- If you want to use static on demand backups with Oracle or SQL Server, we recommend running Datical DB versions 5.6 or higher.
- If you want to use static on demand backups with Postgres, we recommend running Datical DB versions 6.12 or higher.
- Note that if you use backup on_demand, you will NOT get the full benefits of using the schemaName property in the metadata.properties file:
- If you are using backup mode "always", then the schemaName property will limit the schema list to the relevant schemas for three aspects of packager: backup, restore, and snapshot.
- However, if you are using backup mode "on demand" then the schemaName property will limit the schema list to the relevant schemas for only one aspect of packager: snapshot. When you set backup to "on_demand" all of the schemas in the project will be backed up and restored, the schemas for backup/restore will NOT be limited based on the schemaName property.
- Troubleshooting performance time of on_demand static backups: If you are implementing static/on_demand backups but have not seen a significant improvement in how long your packager jobs take to run, check your configuration. If you have set
databaseBackupMode=on_demandbut are still usingcreateDatabaseBackup=truein your main packager jobs that process scripts, that is an unusual configuration. Packager will work with that configuration but it will still create a new backup file for each packager job that processes scripts, and therefore you would NOT be getting the possible performance benefit that you would have in the more typical configuration of creating a nightly backup separately and re-using that backup file when processing scripts (to avoid running backup each time). To optimize the on_demand backup, do NOT usecreateDatabaseBackup=truewith your main packaging job that processes scripts (assuming that the backup file was already created and is in place).
4. For Oracle, you can set the "parallel" property in the deployPackager.properties file for Oracle backup/restore as described in these pages:
- Using the required deployPackager.properties file
- https://docs.oracle.com/database/121/SUTIL/GUID-3081A258-0C23-40B0-8487-9C7A0D248E23.htm#SUTIL921
5. Change your Row Count setting to "approximate" or "disabled" (because "approximate" is significantly faster than "exact") → Settings for Collecting Row Counts
- If you use rules that relate to row count, set this to "approximate". If you do not use rules relating to row count, set this to "disabled".
There are different ways you can set the row count option, use the method you prefer:
- In the desktop client/Eclipse GUI, set it to approximate. See Collect Row Counts During Forecast & Deploy here → Configuring Project Settings
- Set it using the hammer CLI command (example: "hammer set enableRowCount approximate"). See enableRowCount here → CLI Commands#set
- If you use the optional project creator script, see enableRowCount here → Creating a Datical Project Using the Project Creation Script (project_creator.groovy)
6. Use the optional Limited Forecast which is typically faster than Full Forecast, please see this page → Limited Forecast
- Caveat: This could have an impact on Rules enforcement if using Rules.
7. Run packager as a different user than the schema owner (so packager drops the schema and re-creates it, instead of clearing out each object).
8. For Oracle/SQL Server/DB2, change the Stored Logic Validity Check to "local" (the default) or "limited" or "disabled", depending on which features you actively use:
- If you do not review or use the information in the Stored Logic Validity Check section of your deploy reports, then set storedLogicValidityCheck="disabled".
- If you review and use the Stored Logic Validity Check information in your deploy reports but you do not use the storedLogicValidityAction=FAIL option, then set storedLogicValidityCheck="limited".
- If you review and use the Stored Logic Validity Check information in your deploy reports and you also have enabled the storedLogicValidityAction=FAIL option, then set storedLogicValidityCheck="local".
- Although storedLogicValidityCheck="global" is an available setting and is the most comprehensive, if performance timing is important it may be better to use a smaller scope such as "local" or "limited".
- Please see the notes in the "Stored Logic Validity Check" heading on this page: Configuring Project Settings
There are different ways you can set the stored logic validity check level, use the method you prefer to set the value:
- In the desktop client/Eclipse GUI, set it to limited. See Stored Logic Validity Check here → Configuring Project Settings
- Set it using the hammer CLI command (example: "hammer set invalidsCheck limited"). See invalidsCheck here → CLI Commands#set
- If you use the optional project creator script, see invalidsCheck here → Creating a Datical Project Using the Project Creation Script (project_creator.groovy)
- In the datical.project file, this is represented as storedLogicValidityCheck="disabled" or storedLogicValidityCheck="limited" or storedLogicValidityCheck="local".
9. Packaging ddl scripts from the sql_direct folder (packageMethod=direct) is typically faster than from the ddl folder (packageMethod=convert). You could also opt to set packageMethod=direct for your ddl folder.
- Caveat: If you are not using SQL Parser, then only sqlrules would apply in sql_direct folder. (Other types of rules and forecast modeling do NOT apply in the sql_direct folder if you are not using SQL Parser for Oracle.)
- If you are using Oracle with a recent version of Liquibase Enterprise/Datical DB 7.x, you could consider using SQL Parser for Oracle to add forecast modeling and forecast rules.
- When you enable the SQL Parser for Oracle project setting, SQL Parser is applicable by default to the data_dml folder (packageMethod=data_dml) and sql_direct folder (packageMethod=direct) and sql folder (packageMethod=sqlfile).
- You could also opt to set packageMethod=direct for your ddl folder so that folder would also use SQL Parser. Using SQL Parser with packageMethod=direct for ddl would be faster than using the packageMethod=convert for ddl (convert is the default for ddl). You can change the packageMethod for the ddl folder in the metadata.properties file for the ddl folder.
- If your DML scripts are quite large, you could disable SQL Parser for the DATA_DML folder for performance reasons. You can disable SQL Parser at the folder level by setting disableSqlParser=true in the metadata.properties file for the DATA_DML folder. Note that you only need to set disableSqlParser=true for DML in older Datical versions 7.5 and below. Parser is already disabled for DML by default in newer Datical versions 7.6 and higher.
- There were improvements to SQL Parser for Oracle in versions 7.8 and 7.12. We recommend upgrading to a recent 7.x version if you are using SQL Parser for Oracle.
- Please see these pages:
10. Having the build agent and the database in close proximity can help performance.
11. If you have enabled the Automatically Generate SQL setting you may see performance improvements by turning off that project setting.
There are different ways you can disable this setting, use the method you prefer:
- In the desktop client/Eclipse GUI, disable the project setting. See "Automatically generate SQL for Forecast, Deploy, and Rollback" here → Configuring Project Settings
- Disable it using the hammer CLI command (example: "hammer set autoGenSQL false"). See autoGenSQL here → CLI Commands#set
- If you use the optional project creator script, see autoGenSQL here → Creating a Datical Project Using the Project Creation Script (project_creator.groovy)
12. Certain types of script errors (such as missing end delimiter) can cause a packager build job to hang indefinitely during the deploy section of packager. To avoid having this happen, you can set a Script Execution Timeout for your REF environments.
- It is recommended to set it on your REF dbDef step only, not for your higher environments.
- You can configure the number of seconds packager should wait before timing out when deploying a script, for example 600 seconds (10 minutes). You can use the number of seconds that seems appropriate for the types of scripts you typically package. The timeout period is per each individual script.
- If a script is taking longer to deploy than the timeout value, packager build will fail with a timeout error and indicate which script timed out. Having packager fail with a timeout error allows packager to finish all of its steps normally, including restoring/reverting REF DB to its previous state from prior to the error. This is better than having packager hang indefinitely then terminating the job manually, which could leave REF in an unexpected state with an incomplete deployment.
Note that the Script Execution Timeout only applies to changes executed using SQLPlus/SQLCMD/CLPPlus/EDBPlus. It does NOT apply to scripts packaged in the function/procedure/package/view/trigger/sql folders (when using fixed folders) or to folders using packageMethod=STOREDLOGIC or packageMethod=SQLFILE (when using flexible folders).
There are different ways you can set the timeout, use the method you prefer:
- In the desktop client/Eclipse GUI, set it on the REF dbDef step. See "CLPPLus Timeout (seconds)" for DB2, "SQL*Plus Timeout (seconds)" for Oracle, "EDB*Plus Timeout (seconds)" for Postgres, and "SQLCMD Timeout (seconds)" for SQL Server here → Configuring Step Settings (DbDefs)
- Set it using the hammer CLI command (example: "hammer set scriptExecutionTimeout REF 600"). See scriptExecutionTimeout here → CLI Commands#set
- If you use the optional project creator script, see scriptExecutionTimeout here → Creating a Datical Project Using the Project Creation Script (project_creator.groovy)
13. If you don't need to use the Forecast DML project setting, disable it.
There are different ways you can disable this setting, use the method you prefer:
- In the desktop client/Eclipse GUI, go to the Settings tab. Expand the Deployment Settings section. Disable the "Forecast Data Modification Changes (DML)" checkbox.
- Disable it using the hammer CLI command: "hammer set forecastDML false"
- Recommendations for Working with Large DML Scripts
14. Consider increasing the amount of RAM used by Datical using the Xmx setting. See the instructions here: Increase the amount of RAM used by Datical DB
15. Upgrade to a current version of Datical:
- There were performance improvements during the forecast stage for those who run deployPackager on Windows clients or Windows agents in Datical DB version 6.8 (and higher).
- There were performance improvements for those who use the Stored Logic Validity Check project setting in Datical DB version 6.12 (and higher).
- There were performance improvements for several operations in Datical DB version 6.14 (and higher). Areas where you may notice performance improvements:
- Status/Pipeline Status operations in the Datical DB GUI
- 'status' & 'statusDetails' commands in the CLI
- Complex operations which run status implicitly (CLI & GUI) - All types of 'deploy' operations, All types of 'rollback' operations, Deploy Packager, Convert SQL, and Change Log Sync
- There were performance improvements specifically for multi-database/multi-catalog configurations of SQL Server projects in Datical DB version 6.16 (and higher).
- There is a fix for the DATAPUMP API Oracle backup and restore in Datical DB version 6.16 (and higher) to better handle running multiple packager jobs concurrently.
- There is a new cleanup command for packager in Datical DB versions 7.3 (and higher). The cleanup command can be run after any time that you might need to manually interrupt a packager build job midway. The cleanup command is to unblock subsequent packager jobs after a manual interruption by clearing the locks on DATABASECHANGELOGLOCK and DATICAL_SPERRORLOG tables and also restoring REF. Please see this page for more details: How To: Use ReleaseLocks Command and Packager with Cleanup Option
- With Datical DB version 7.6 (and higher), there is a new feature that prevents continuing to run packager jobs after a backup error or restore error. Please see the "Recovering from a Backup or Restore Failure" section here for more details: https://datical-cs.atlassian.net/wiki/spaces/DDOC/pages/896570174/Managing+Database+Backup+and+Restore#ManagingDatabaseBackupandRestore-RecoveringfromaBackuporRestoreFailure
- There were improvements for memory utilization of SQL scripts that produce a high-volume output in 7.11 (and higher).
- There were improvements for SQL Parser for Oracle in versions 7.8 and 7.12. If you are using SQL Parser for Oracle, we recommend running a recent 7.x version.
16. Although not specifically about packager, it may also be useful to check the items on these pages that may improve Deploy performance:
Related articles